


Kiwis pequeños y setas venenosas (#18 de 2024)
Exploramos cómo cambia el nivel de comprensión de los modelos de lenguaje según su tamaño.

Vamos con una continuación del artículo de la semana pasada. Me gustó mucho el engaño utilizado en el artículo que mencionamos de Apple para demostrar los problemas a los que se enfrentan los modelos de lenguaje con el razonamiento, y he estado modificándolo y probándolo con distintos modelos. Sin embargo, mi objetivo no es investigar el tema del razonamiento, sino explorar el otro aspecto que mencionamos: el de la comprensión.
Por si no tienes tiempo de leer hasta el final, adelanto las conclusiones de estas pruebas. Los experimentos que vamos a detallar muestran cómo: (1) los LLMs poseen una comprensión del lenguaje natural que influye en su competencia en los razonamientos que realizan, y (2) cuanto mayor es el LLM, más abstracta resulta ser esta comprensión.
No estoy descubriendo nada nuevo. Que los LLMs puedan configurarse mediante lenguaje natural para mejorar su competencia es algo conocido desde los inicios de los chatbots, cuando se filtraron los prompts de Sydney. Además, que el tamaño del LLM aumente su capacidad de abstracción es un tema que hemos tratado en varias ocasiones al mencionar la hipótesis de escalado. Pero en este artículo, vamos a ofrecer ejemplos sencillos que nos permitirán comprender mejor estas ideas.
¡Gracias por leerme!

Un kiwi pequeño sigue siendo un kiwi
Empecemos explicando la trampa que los investigadores de Apple tienden a los LLMs. La analizan en detalle en su artículo, donde explican cómo basta con añadir algún dato aparentemente irrelevante a un enunciado de un problema de primaria para confundir al LLM y hacer que no lo resuelva correctamente.
Primero, veamos el enunciado sin trampa. Es sencillo, pero requiere un poco de razonamiento:
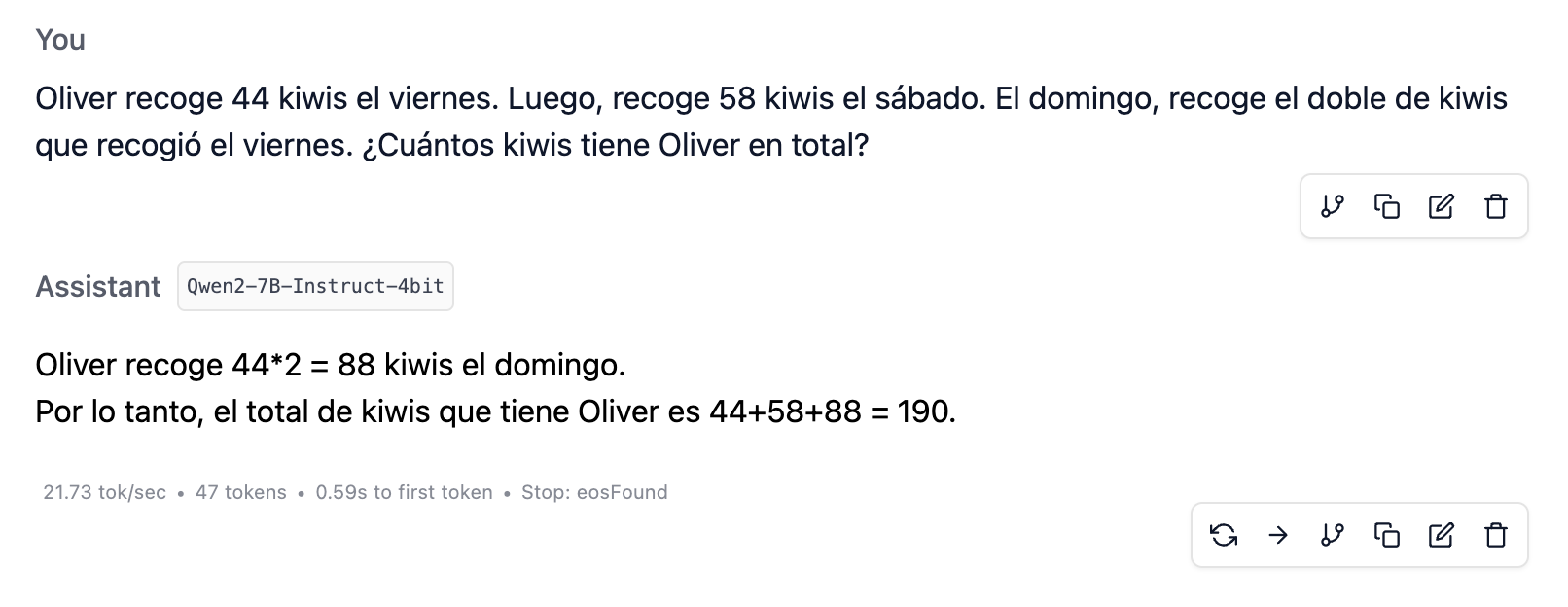
Oliver recoge 44 kiwis el viernes. Luego, recoge 58 kiwis el sábado. El domingo, recoge el doble de kiwis que recogió el viernes. ¿Cuántos kiwis tiene Oliver en total?
He descargado LM Studio en mi MacBook Air (M3 con 16 GB de RAM) y he probado los modelos pequeños Qwen2-7B-Instruct-4bit y Meta-Llama-3.1-8B-Instruct-4bit. Ambos lo resuelven sin problema, como se muestra en la imagen.
Podría parecer que los modelos están razonando, pero los autores demuestran que no es así mediante un truco muy ingenioso. Añaden un dato irrelevante al enunciado, concretamente la siguiente frase (la frase añadida está en negrita):
Oliver recoge 44 kiwis el viernes. Luego, recoge 58 kiwis el sábado. El domingo, recoge el doble de kiwis que recogió el viernes, pero cinco de ellos eran más pequeños que la media. ¿Cuántos kiwis tiene Oliver en total?
La mención de que cinco de los kiwis son más pequeños es irrelevante. Esos kiwis deberían contarse igual, y Oliver debería seguir teniendo 190 kiwis en total. Sin embargo, estos LLMs básicos se confunden y los descuentan. A continuación, mostramos la imagen de Llama-3.1-8B.

¿Por qué se confunden? Porque aplican de forma literal un patrón que han aprendido: al encontrar una frase del tipo “pero bla, bla, bla”, tienden a restar los ítems mencionados en el “bla, bla, bla”. No se dan cuenta de que es irrelevante que cinco kiwis sean más pequeños.
Los modelos pequeños son inflexibles
En el artículo de Melanie Mitchell, que también comentábamos la semana pasada, se enlazaba a un tweet en el que se sugería que otra posible explicación del fallo de los LLMs era la falta de contexto suficiente. Puede que los LLMs, entrenados para conversar, se confundan porque interpretan que, por ejemplo, a Oliver no le gustan los kiwis pequeños. Deberíamos explicar al LLM que se trata de un ejercicio de matemáticas. En el tweet se dice:
Mi conjetura es que, por ejemplo, con algo de prompt engineering con la que le explicáramos al LLM que esto es un examen de matemáticas, probablemente la mayoría de estos problemas desaparecerían.
Pues bien, no es así. Al menos con estos modelos pequeños. Por mucha explicación que he añadido, no he conseguido que los modelos pequeños dejen de confundirse. He probado con varias introducciones al problema, como las siguientes:
"Resuelve el siguiente problema de matemáticas."
"Supongamos que estás en clase de matemáticas y el profesor te pone el siguiente problema. "
"Supongamos que estás en clase de matemáticas y el profesor te pone el siguiente problema. Es un profesor bastante quisquilloso, que a veces pone problemas que tienen alguna trampa en el enunciado."
Incluso indicándoles explícitamente que no deben confundirse con detalles irrelevantes, no obtengo buenos resultados:
"Supongamos que estás en clase de matemáticas y el profesor te pone el siguiente problema. Debes sumar todos los kiwis, independientemente de su tamaño."
"Debes sumar todos los kiwis, no restes los que son más pequeños de lo normal."
"Debes sumar TODOS los kiwis. NO DEBES RESTAR los que son más pequeños de lo normal. "
La última instrucción es la más directa posible, con frases en mayúscula para resaltar su importancia, y ni siquiera así funcionan bien:

Cuando ves esto, te das cuenta de la fe que debieron tener los investigadores de OpenAI para no desanimarse con los primeros modelos.
Los modelos grandes no se confunden fácilmente
Vamos ahora a probar con LLMs mucho más grandes: ChatGPT 4o y 4o mini. Dejamos fuera el modelo o1 porque no es un LLM puro.
Los modelos pequeños anteriores cuentan con 8 mil millones de parámetros (8B). OpenAI no ha hecho público el número de parámetros de GPT-4o, pero sabemos que GPT-3.5 tenía 175 mil millones (175B), y se rumorea que GPT-4 tiene algo más de un billón (1.000B). No importa demasiado, ya que estamos realizando un experimento sin mucho rigor científico, así que basta con considerar los órdenes de magnitud:
Los modelos pequeños anteriores tienen 8B parámetros.
GPT-4o cuenta con alrededor de dos órdenes de magnitud más (100x).
Presumiblemente, 4o mini es algo más pequeño que 4o.
Al probar el problema original de los kiwis, vemos que este salto de dos órdenes de magnitud se nota bastante: ChatGPT 4o lo resuelve siempre perfectamente.

Fue una pequeña decepción que funcionaran tan bien, ya que no podía realizar los experimentos previos de añadir contexto antes del problema. Entonces, se me ocurrió enredar un poco más el problema: ¿y si en lugar de hablar de kiwis pequeños mencionamos setas venenosas?
Oliver recoge 44 setas el viernes. Luego, recoge 58 setas el sábado. El domingo, recoge el doble de setas que recogió el viernes, pero cinco de ellas eran venenosas. ¿Cuántas setas tiene Oliver en total?
Aquí las posibilidades de confusión son mucho mayores. De hecho, si no lo consideramos un problema de matemáticas, muchos diríamos que la respuesta es 185, porque asumiríamos que Oliver está recogiendo setas para después comérselas. En efecto, tanto 4o como 4o mini responden de esta forma. 4o incluso especifica que se refiere a “setas comestibles”:
Ahora, sumamos todas las setas comestibles:
44 + 58 + 83 = 185Respuesta: Oliver tiene un total de 185 setas comestibles.
Perfecto, es justo lo que buscaba. Ahora puedo empezar a añadir contexto y experimentar cuánta información es necesaria para que ChatGPT considere que hay que sumar todas las setas, sean comestibles o no.
Por cierto, es curioso (y nos dice bastante de la capacidad de comprensión de estos modelos) que al cambiar el enunciado y mencionar que Oliver “hace fotos” en lugar de “recoger” setas, los modelos ya no se confunden:
Oliver hace fotos a 44 setas el viernes. Luego, hace fotos a 58 setas el sábado. El domingo, hace fotos al doble de setas que hizo el viernes, pero cinco de ellas eran venenosas. ¿Cuántas fotos de setas tiene Oliver en total?
Tanto 4o como 4o mini responden siempre 190, reconociendo que, para obtener fotos de las setas, no importa si son venenosas o no.
Cuanto mayor es el modelo, más abstractas pueden ser las indicaciones
Ya tenemos entonces el problema que causa confusión en los modelos grandes:
Oliver recoge 44 setas el viernes. Luego, recoge 58 setas el sábado. El domingo, recoge el doble de setas que recogió el viernes, pero cinco de ellas eran venenosas. ¿Cuántas setas tiene Oliver en total?
Lo que hice fue, igual que con los modelos pequeños, ir añadiendo una explicación al principio, para contextualizar el problema, y probarlo tanto en 4o como en 4o mini. Puedes probarlo tú también para comprobar si te salen los mismos resultados. Recuerda que debes iniciar un chat nuevo cada vez.
Comenzamos añadiendo la frase “Resuelve el siguiente problema de matemáticas”. No funciona; este contexto no es suficiente, y ambos modelos responden incorrectamente.
Añadimos más contexto: “Supongamos que estás en clase de matemáticas y el profesor te plantea el siguiente problema. ¿Qué contestarías?”. Tampoco funciona.
Añadimos aún más contexto, aunque de forma sutil, para que la pista no sea tan directa: “Supongamos que estás en clase de matemáticas y el profesor te plantea el siguiente problema. Es un profesor bastante quisquilloso, que a veces incluye trampas en los enunciados. ¿Qué contestarías?” Ahora sí, esta frase es suficiente para que 4o acierte alrededor de la mitad de las veces (recordemos que los LLMs son modelos estocásticos), respondiendo en ocasiones que tiene 190 setas. Sin embargo, 4o mini sigue contestando incorrectamente.
Luego, damos una indicación más concreta: “Debes considerar todos los ítems recogidos, sean comestibles o no”. Esto permite que 4o acierte casi siempre y diga 190 setas, mientras que 4o mini solo acierta algunas veces.
Finalmente, al cambiar “ítems” por “setas”, ambos modelos responden siempre correctamente, tanto 4o como 4o mini. El contexto completo sería: “Resuelve el siguiente problema de matemáticas. Debes considerar todas las setas recogidas, sean comestibles o no.”
Resumiendo los experimentos, al presentar el problema a ChatGPT 4o y 4o mini, ambos modelos inicialmente fallaron al interpretarlo, descontando las setas venenosas en lugar de sumarlas. La idea de que no deben contar las setas venenosas es demasiado potente y difícil de eliminar. Sin embargo, cuando introdujimos la posibilidad de que “intenten ponerte una trampa”, 4o empezó a acertar algunas veces. Luego, al añadir indicaciones concretas de sumar todos los ítems, 4o respondió correctamente casi siempre, mientras que 4o mini aún no pudo aplicar esta misma abstracción, requiriendo que sustituyéramos “ítems” por “setas” para responder correctamente.
Estos experimentos ilustran de forma muy gráfica cómo, una vez superado cierto tamaño, los LLMs pueden ser orientados y corregidos mediante explicaciones en lenguaje natural. Y ademas, que cuanto mayor es el tamaño del modelo, más abstractas pueden ser esas explicaciones.
¿Qué sucederá en un futuro próximo, cuando OpenAI, Google y Meta lancen la siguiente generación de modelos de lenguaje que están cocinando en sus laboratorios? Es previsible que los modelos futuros, de mayor tamaño, sean mucho más receptivos a las indicaciones y correcciones en lenguaje natural. Cuando cometan un error, será mucho más sencillo guiarlos y corregirlos, comprenderán conceptos más abstractos, y podremos encargarles tareas más complejas.
Se equivocarán en muchas ocasiones, pero, al igual que con colegas humanos, bastará con ofrecerles explicaciones adicionales para aclarar la situación. No nos frustraremos intentando corregirlos sin éxito, será fácil orientarlos para alinearlos con nuestro contexto. Los consideraremos herramientas con las que podremos explorar problemas y encontrar soluciones juntos.
Creo que estamos ya muy cerca de alcanzar este nivel de asistente humano. No será aún una AGI, pero será muy útil y nos ahorrará mucho trabajo.
¡Hasta la próxima, nos leemos! 👋👋