


o3 resuelve ARC-AGI
20/12/2024: un día histórico para la IA

Cuando a principios de la semana envié el último artículo, pensaba que iba a ser el último del año. Quería terminar el año hablando del dogma del deep learning, abriendo el camino para una futura continuación en la que hablara sobre la consciencia. Y quería dejar quieta la newsletter unas semanas y trabajar poco a poco, con tranquilidad, en este nuevo artículo.
De hecho, le he cambiado el título a la newsletter, ya no se llama Quince días. Así me quito la presión de tener que hacer dos entregas mensuales y de contar la actualidad. Ya hay otras newsletters muy interesantes de noticias de IA. Quiero continuar con el enfoque que le he dado en los últimos números, en los que toco con cierta profundidad algún tema, que no tiene por qué ser de actualidad.
Pero el viernes pasó algo que hay que contar aquí, sí o sí.
OpenAI ha hecho públicos unos resultados impresionantes de su nuevo modelo razonador o3, la siguiente versión de o1. A continuación está el vídeo con la presentación:
Todos los resultados que presentan muestran un salto espectacular en los benchmarks más complicados. Por ejemplo, pasan del 48,9% al 71,7% en SWE-bench Verified, un benchmark de problemas de programación. O pasan del 3% al 25% en el “AI's Frontier Math”, un test que está compuesto de problemas de matemáticas del nivel de doctorado.
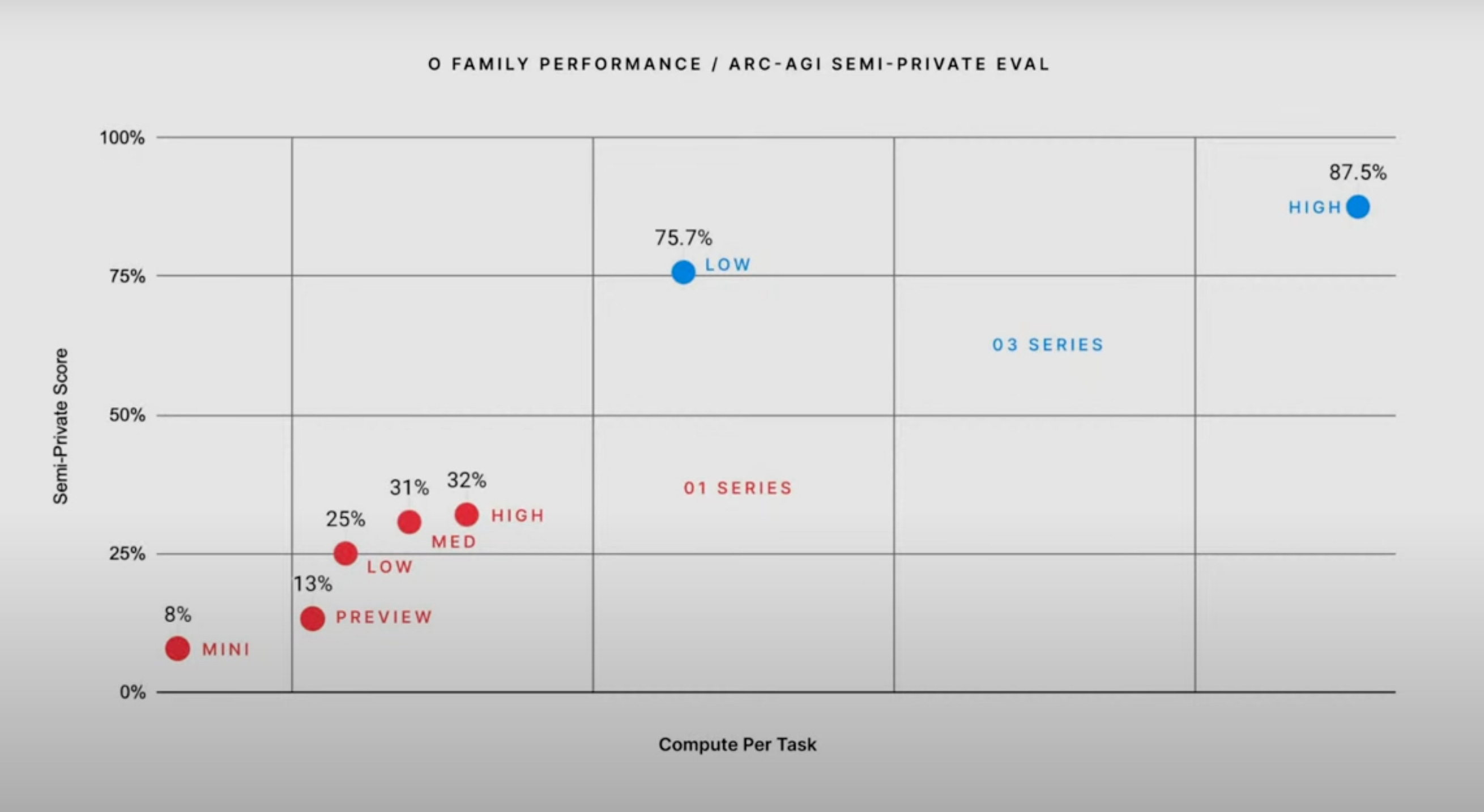
Pero lo que ha sido realmente sorprendente ha sido que han conseguido resolver la competición ARC-AGI de François Chollet. En el vídeo de presentación de o3, mostraron la figura anterior, en la que se muestra cómo o3 ha conseguido acertar un 75,7% en su versión "low" y un 87% en su versión "high".
¿Qué es esto de "low" y "high"? Como vimos en el artículo en el que hablamos de cómo funciona o1, estos modelos razonadores pueden afinar sus resultados cuando tienen más tiempo de computación. Los modos "low" y "high" son denominaciones que han dado los investigadores de OpenAI a un funcionamiento de o3 con poco tiempo de computación y con mucho tiempo de computación. En la gráfica también se muestra que el tiempo de computación del modo "low" de o3 es significativamente mayor que el del modo "high" de o1 que consigue un 32% (no dicen si la escala horizontal es lineal o logarítmica, supongo que será lineal, igual que la vertical).
En el momento en que en la retransmisión de OpenAI apareció Greg Kamradt, presidente del premio ARC, y explicó todo lo anterior, me explotó la cabeza. No me lo terminaba de creer. Fui corriendo a X a comprobar las reacciones, empecé a ver los posts de gente relacionada con la competición, y, por fin, cuando vi la reacción del propio Chollet fue cuando confirmé que era real. El equipo de OpenAI responsable de los modelos “o” había hecho algo histórico, resolver ARC-AGI. Se había resuelto en tres meses, desde la presentación de o1, un reto propuesto para identificar capacidades de razonamiento y de inteligencia humana.
¿Qué implicaciones tiene este enorme éxito en el desarrollo de o3?
La implicación más importante es que se valida el enfoque de la serie de modelos razonadores "o", y se comprueba que estos modelos integran perfectamente la intuición (System 1) de los LLMs tradicionales con algún tipo de razonamiento System 2 deductivo e iterativo. OpenAI ha encontrado los ingredientes de la sopa definitiva, la que permite combinar los dos tipos de razonamiento de los que hablamos en el artículo sobre Chollet. Esta combinación es clave para el futuro, porque garantiza la mejora continua de los modelos. Por un lado, cuando se consiga un nuevo modelo intuitivo mejor (GPT-5) se integrará fácilmente en el nuevo modelo "o". Y cuando se mejoren las capacidades deductivas y se abarate el coste de computación también se podrá conseguir mejoras sustanciales.
Otra implicación fundamental es que se confirma el papel de NVIDIA y de los fabricantes de chips. Y de la energía necesaria para alimentarlos. Quien tenga más MegaFLOPS será el que mejores resultados obtenga. Ilya Sutskever acaba de decir que los datos son la nueva energía fósil. También lo es la potencia de computación.
Por último, hay que destacar la enorme suerte (o el bien hacer) de OpenAI, que ha podido terminar el año con un avance espectacular y ha encontrado con los modelos "o" una forma de avanzar en su camino hacia la AGI sin tener que echar mano de su siguiente modelo GPT. Hoy mismo, en el Wall Street Journal, se detallan todos los problemas que están teniendo para desarrollar GPT-5. Parece que los dos o tres pre-trainings que OpenAI ha intentado han fracasado después de meses de computación. Un modelo 10 veces más grande que GPT-4 necesita también 10 veces más cantidad de datos (como mínimo) y parece que están teniendo problemas con eso. El debate sobre si existe un muro en el deep learning todavía no se ha resuelto.
También hay que aclarar que, aunque el éxito de o3 ha sido espectacular, todavía no hemos alcanzado la AGI. Hay muchos elementos que faltan por integrar en estos modelos, como la posibilidad de razonar con un modelo físico del mundo, el aprendizaje continuo o la creatividad.
Seguiremos muy atentos durante 2025 a estos temas básicos de investigación sobre el deep learning y los modelos de lenguaje, que marcarán el futuro de la tecnología.
Mientras, los avances que hemos visto en este 2024 dan para muchísimas aplicaciones que todavía están pendientes de desarrollar con los modelos ya disponibles.
Esto no para.
¡Hasta la próxima, nos leemos! 👋👋